Emulation Wrap-Up and Class Review
Lecture 22
May 1, 2024
Benefits of Model Simplicity
- More thorough representation of uncertainties
- Can focus on “important” characteristics for problem at hand
- Potential increase in generalizability

Source: Helgeson et al. (2021)
Factor Prioritization
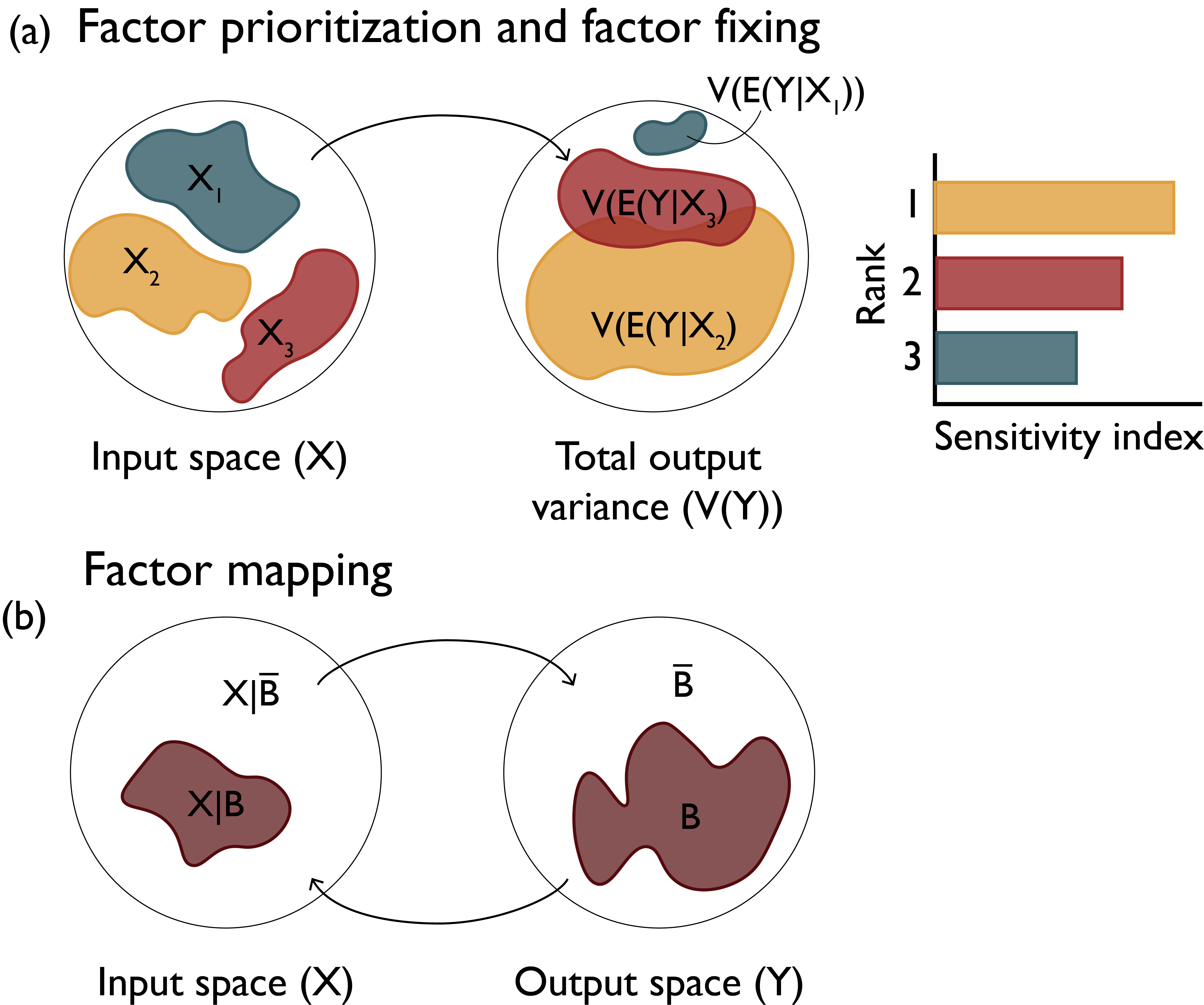
Source: Reed et al. (2022)
Types of Sensitivity Analysis
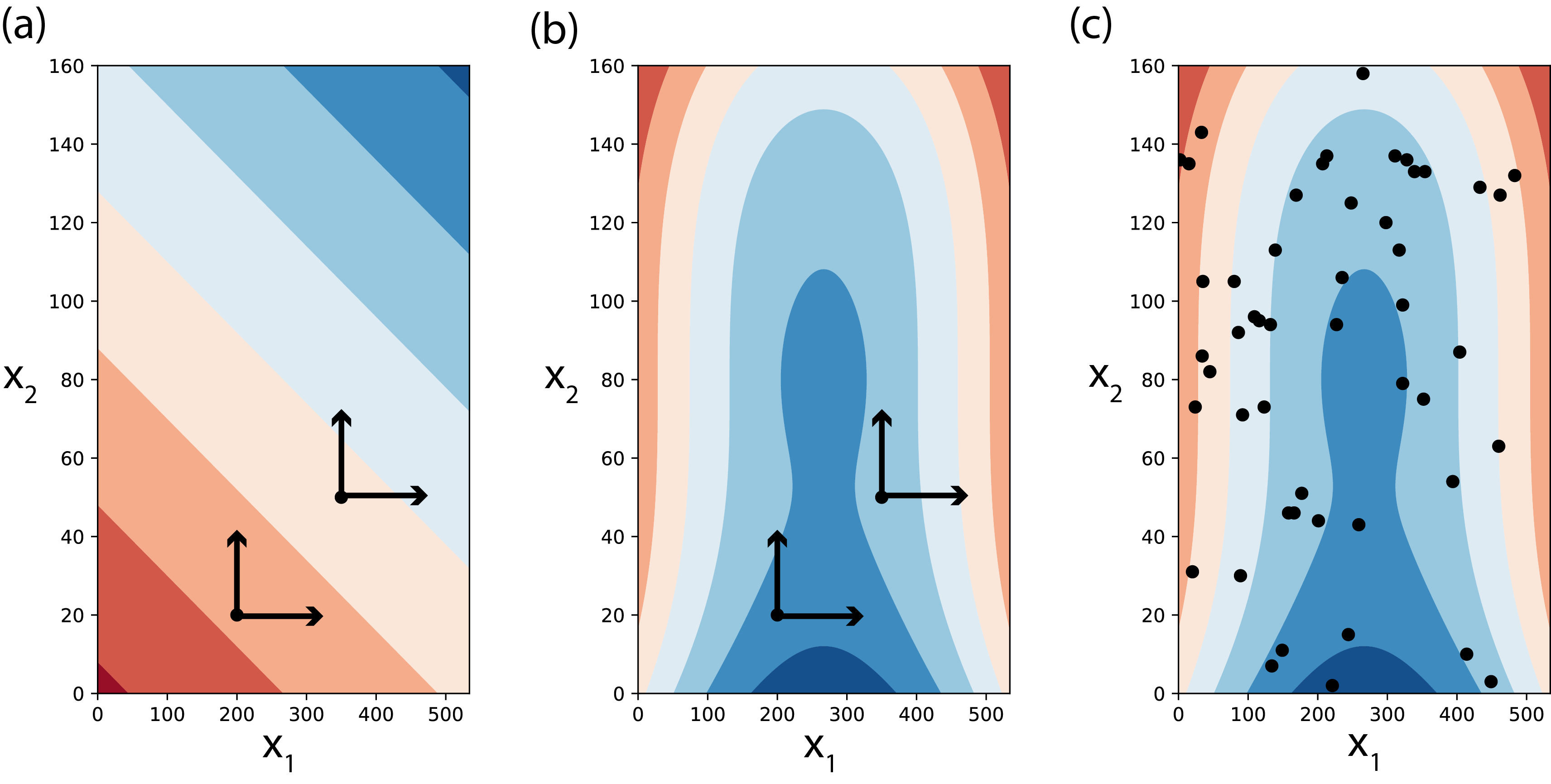
Source: Reed et al. (2022)
Design of Experiments
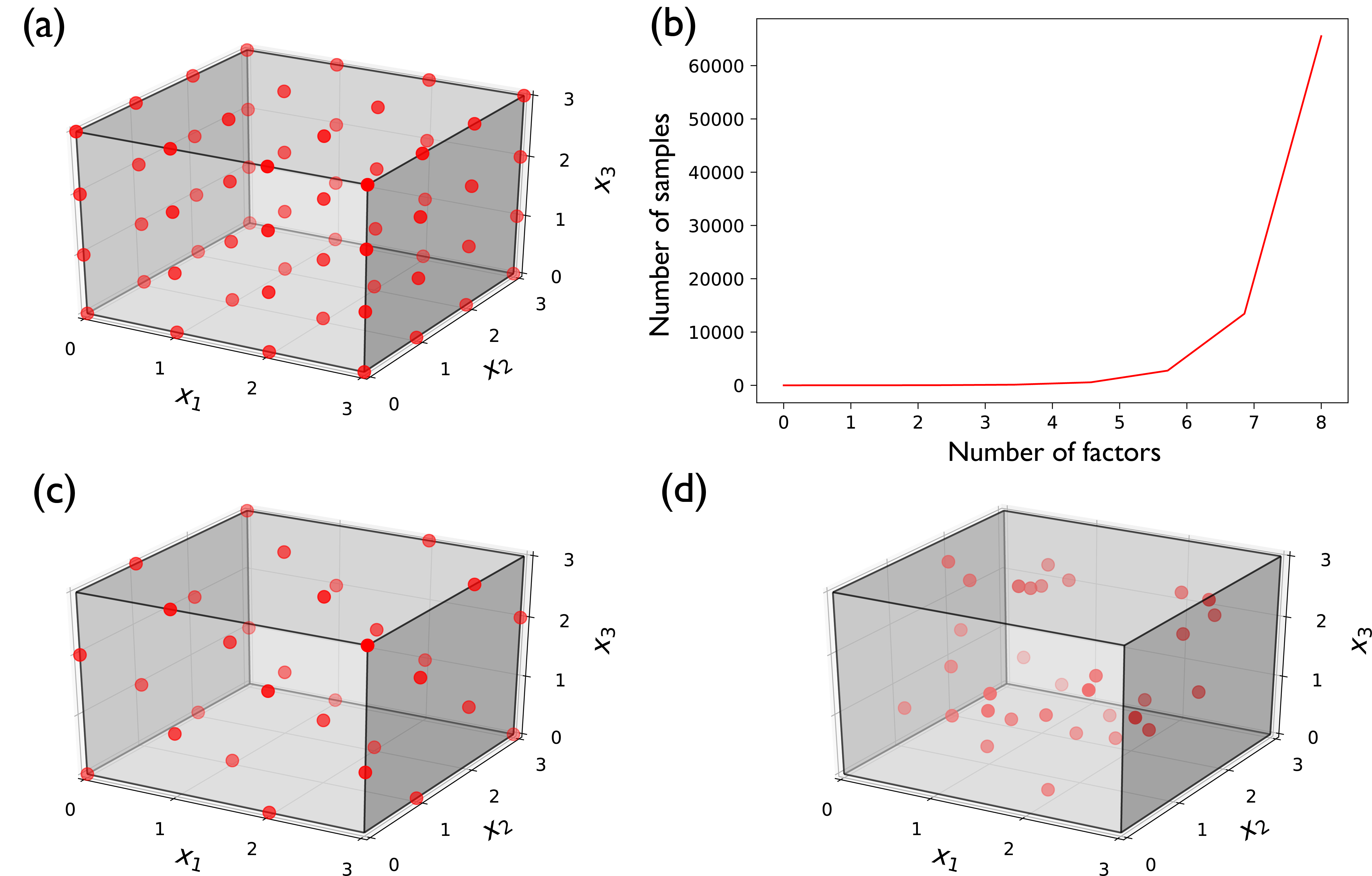
Source: Reed et al. (2022)
The Ideal
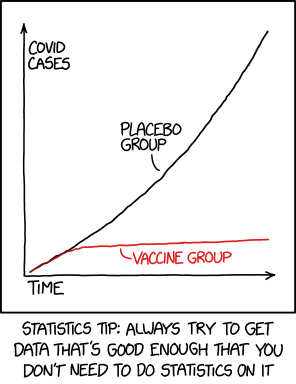
Source: XKCD 2400
Modes of Data Analysis
