Key Idea: Model selection consists of navigating the bias-variance tradeoff.
Bias and Variance
Model error (e.g. MSE) is a combination of irreducible error, bias, and variance.
Bias can come from under-dispersion (too little complexity) or neglected processes;
Variance can come from over-dispersion (too much complexity) or poor identifiability.
Cross-Validation
Cross-validation is the gold standard for predictive accuracy: how well does the fitted model predict out of sample data?
Cross-Validation
The problems:
Leave-one-out CV can be very computationally expensive!
We often don’t have a lot of data for calibration, so holding some back can be a problem.
How to divide data with spatial or temporal structure? This can be addressed by partitioning the data more cleverly (e.g. leaving out future observations), but makes the data problem worse.
Information Criteria
Approximate LOO-CV by computing fit on calibration/training data and “correcting” for expected overfitting.
Examples (differ in the parameter values used and correction factor(s)):
AIC
DIC
WAIC
Model Weighting
Information Criteria can be used to get averaging weights across a model set \(\mathcal{M} = \{M_1, \ldots, M_m\}\):
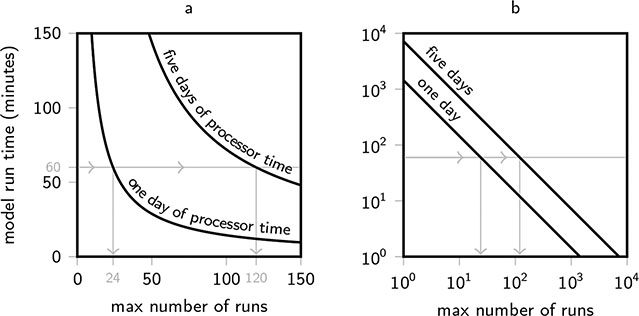
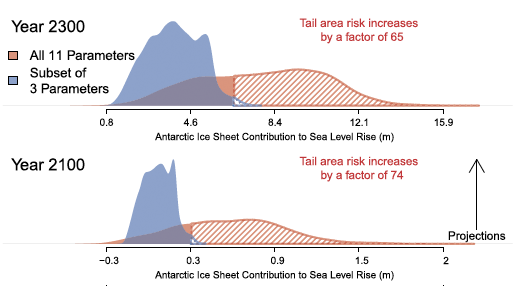
Model simplicity can be valuable for focusing on key dynamics and uncertainty representation.
Tradeoff between computational expense and fidelity of approximation.
Key Takeaways (Emulation)
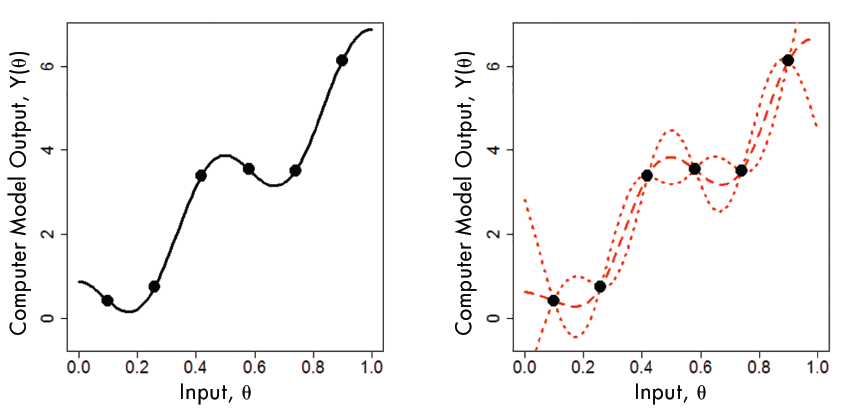
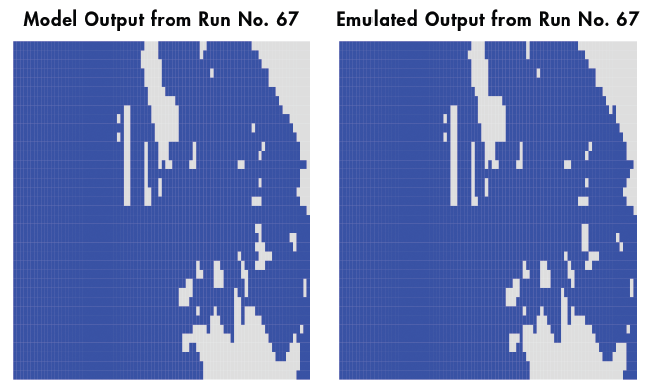
Emulation can “simplify” complex models by approximating response surfaces
Emulator methods have different pros and cons which can make them more or less important.
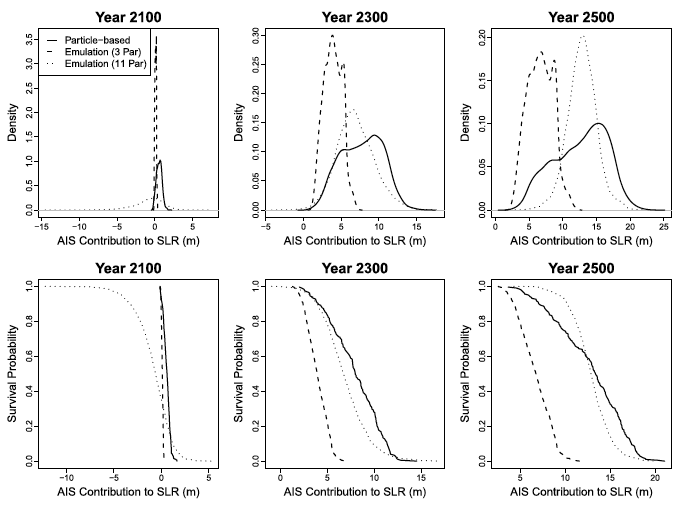
Emulator error can strongly influence resulting risk estimates.
Upcoming Schedule
Wednesday: Emulation Methods
Friday: HW4 due
Next Monday: Project Presentations, email slides by Saturday.
References
References
Bürkner, P.-C., Gabry, J., & Vehtari, A. (2020). Approximate leave-future-out cross-validation for bayesian time series models. J. Stat. Comput. Simul., (14), 2499–2523. https://doi.org/10.1080/00949655.2020.1783262
Haran, M., Chang, W., Keller, K., Nicholas, R., & Pollard, D. (2017). Statistics and the future of the antarctic ice sheet. Chance, 30(4), 37–44. https://doi.org/10.1080/09332480.2017.1406758
Helgeson, C., Srikrishnan, V., Keller, K., & Tuana, N. (2021). Why simpler computer simulation models can be epistemically better for informing decisions. Philos. Sci., 88(2), 213–233. https://doi.org/10.1086/711501
Lee, B. S., Haran, M., Fuller, R. W., Pollard, D., & Keller, K. (2020). A fast particle-based approach for calibrating a 3-D model of the antarctic ice sheet. Ann. Appl. Stat., 14(2), 605–634. https://doi.org/10.1214/19-AOAS1305
Vehtari, A., Gelman, A., & Gabry, J. (2017). Practical bayesian model evaluation using leave-one-out cross-validation and WAIC. Stat. Comput., 27(5), 1413–1432. https://doi.org/10.1007/s11222-016-9696-4
Yao, Y., Vehtari, A., Simpson, D., & Gelman, A. (2018). Using stacking to average Bayesian predictive distributions. arXiv [Stat.ME]. https://doi.org/10.1214/17-BA1091