Then the bootstrap error distribution approximates the sampling distribution \[(\tilde{t}_i - \hat{t}) \overset{\mathcal{D}}{\sim} \hat{t} - t_0\]
The Non-Parametric Bootstrap
The non-parametric bootstrap is the most “naive” approach to the bootstrap: resample-then-estimate.
Non-Parametric Bootstrap
Why Use The Bootstrap?
Do not need to rely on variance asymptotics;
Can obtain non-symmetric CIs.
Approaches to Bootstrapping Structured Data
Correlations: Transform to uncorrelated data (principal components, etc.), sample, transform back.
Time Series: Block bootstrap
Generalizing the Block Bootstrap
The rough transitions in the block bootstrap can really degrade estimator quality.
Improve transitions between blocks
Moving blocks (allow overlaps)
Sources of Non-Parametric Bootstrap Error
Sampling error: error from using finitely many replications
Statistical error: error in the bootstrap sampling distribution approximation
When To Use The Non-Parametric Bootstrap
Sample is representative of the data distribution
Doesn’t work well for extreme values!
The Parametric Bootstrap
The Parametric Bootstrap
Non-Parametric Bootstrap: Resample directly from the data.
Parametric Bootstrap: Fit a model to the original data and simulate new samples, then calculate bootstrap estimates.
This lets us use additional information, such as a simulation or statistical model.
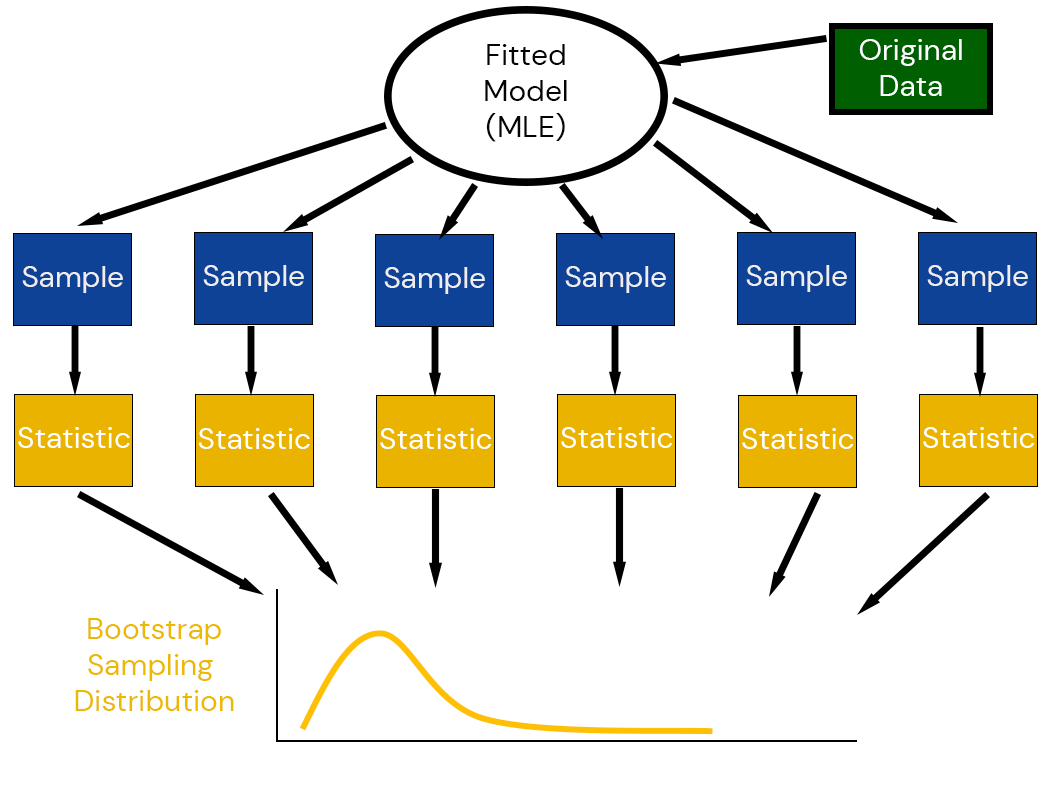
Parametric Bootstrap Scheme
The parametric bootstrap generates pseudodata using fitted model simulations.
Parametric Bootstrap
Benefits of the Parametric Bootstrap
Can quantify uncertainties in parameter values
Deals better with structured data (model accounts for structure)
Potential Drawbacks
New source of error: model specification
Misspecified models can completely distort estimates.
Example: 100-Year Return Periods
Detrended San Francisco Tide Gauge Data:
Code
# read in data and get annual maximafunctionload_data(fname) date_format =DateFormat("yyyy-mm-dd HH:MM:SS")# This uses the DataFramesMeta.jl package, which makes it easy to string together commands to load and process data df =@chain fname begin CSV.read(DataFrame; header=false)rename("Column1"=>"year", "Column2"=>"month", "Column3"=>"day", "Column4"=>"hour", "Column5"=>"gauge")# need to reformat the decimal date in the data file@transform:datetime =DateTime.(:year, :month, :day, :hour)# replace -99999 with missing@transform:gauge =ifelse.(abs.(:gauge) .>=9999, missing, :gauge)select(:datetime, :gauge)endreturn dfenddat =load_data("data/surge/h551.csv")# detrend the data to remove the effects of sea-level rise and seasonal dynamicsma_length =366ma_offset =Int(floor(ma_length/2))moving_average(series,n) = [mean(@view series[i-n:i+n]) for i in n+1:length(series)-n]dat_ma =DataFrame(datetime=dat.datetime[ma_offset+1:end-ma_offset], residual=dat.gauge[ma_offset+1:end-ma_offset] .-moving_average(dat.gauge, ma_offset))# group data by year and compute the annual maximadat_ma =dropmissing(dat_ma) # drop missing datadat_annmax =combine(dat_ma -> dat_ma[argmax(dat_ma.residual), :], groupby(transform(dat_ma, :datetime =>x->year.(x)), :datetime_function))delete!(dat_annmax, nrow(dat_annmax)) # delete 2023; haven't seen much of that year yetrename!(dat_annmax, :datetime_function =>:Year)select!(dat_annmax, [:Year, :residual])dat_annmax.residual = dat_annmax.residual /1000# convert to m# make plotsp1 =plot( dat_annmax.Year, dat_annmax.residual; xlabel="Year", ylabel="Annual Max Tide (m)", label=false, marker=:circle, markersize=5, tickfontsize=16, guidefontsize=18)p2 =histogram( dat_annmax.residual, normalize=:pdf, orientation=:horizontal, label=:false, xlabel="PDF", ylabel="", yticks=[], tickfontsize=16, guidefontsize=18)l =@layout [a{0.7w} b{0.3w}]plot(p1, p2; layout=l, link=:y, ylims=(1, 1.7), bottom_margin=10mm, left_margin=5mm)plot!(size=(1000, 350))
Figure 1: Annual maxima surge data from the San Francisco, CA tide gauge.
Parametric Bootstrap Strategy
Fit GEV Model
Compute 0.99 Quantile
Repeat \(N\) times:
Resample Extreme Values from GEV
Calculate 0.99 quantile.
Compute Confidence Intervals
Parametric Bootstrap Results
Code
# function to fit GEV model for each data setinit_θ = [1.0, 1.0, 1.0]gev_lik(θ) =-sum(logpdf(GeneralizedExtremeValue(θ[1], θ[2], θ[3]), dat_annmax.residual))# get estimates from observationsrp_emp =quantile(dat_annmax.residual, 0.99)θ_mle = Optim.optimize(gev_lik, init_θ).minimizerp =histogram(dat_annmax.residual, normalize=:pdf, xlabel="Annual Maximum Storm Tide (m)", ylabel="Probability Density", tickfontsize=16, guidefontsize=18, label=false, right_margin=5mm, bottom_margin=5mm, legendfontsize=18, left_margin=5mm)plot!(p, GeneralizedExtremeValue(θ_mle[1], θ_mle[2], θ_mle[3]), linewidth=3, label="Parametric Model")vline!(p, [rp_emp], color=:red, linewidth=3, linestyle=:dash, label="Empirical Return Level")xlims!(p ,0, 2)
Rahmstorf, S., & Coumou, D. (2011). Increase of extreme events in a warming world. Proceedings of the National Academy of Sciences, 108, 17905–17909. https://doi.org/10.1073/pnas.1101766108